Python3—笔记
部分内容来自知乎和中国大学mooc
[toc]
1. Python概述
1.1 代码编写方式:
- 交互式
- 全部编辑好后运行
1.2 作用域
- 默认使用 ‘缩进’ 来区分代码 属于哪部分
1.3 注释
- 单行 # 注释内容
- 多行 ''’ 注释内容''’
1 | # 这是单行注释 |
1.4 输入——input()
1 | # 括号内为提示信息,输入的信息存储在变量 name 中 |
1.5 输出——print()
1 | #单个字符串 |
1.6 数据类型
注意: 整数 和 浮点数 在计算机内部存储的方式是不同的,整数 运算永远是精确的(除法也是精确的),而浮点数 运算则可能会有四舍五入的误差。
1.6.1 int
1 | #十进制 |
1.6.2 float
1 | #对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代, |
1.6.3 str
1 | #使用单引号或者双引号包裹 |
1.6.4 bool
1 | #布尔值只有True、False两种值,布尔值可以用and、or和not运算 |
1.6.5 None 空值
1.6.6 list (有序列表)
1 | ''' |
1.6.7 tuple (元组)
一种内部元素不可更改的list , 相较于 list 更安全
1 | ############# tuple 的定义 ############### |
1.6.8 dict (字典)
字典: 内部为键值对,键 在该字典中必须唯一 ,字典是无序的
1 | ''' |
1.6.9 set (集合)
集合类型 : 要创建一个set,需要提供一个list作为输入集合, set是无序的, 重复元素在set中自动被过滤 ,与dict一样内部元素不可变
1 |
|
1.7 运算符
1 | # + |
1.8 条件判断
1 | ''' |
1.9 循环
1 | ################# for 循环 ###################### |
1.10 编码: Unicode ,ASCII ,UTF-8
- ASCII编码和Unicode编码的区别:
- ASCII编码 是 1个字节,而 Unicode编码 通常是2个字节。
- 文本上全部是英文时,Unicode 编码 比 ASCII 编码 需要多一倍的存储空间,在存储和传输上就十分不划算。
- 把Unicode编码转化为“可变长编码”的 UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
- 传输的文本包含大量英文字符时,用 UTF-8编码 更节省空间 。
1.11 函数
1.11.1 内置函数 速查表
官网: https://docs.python.org/3/library/functions.html 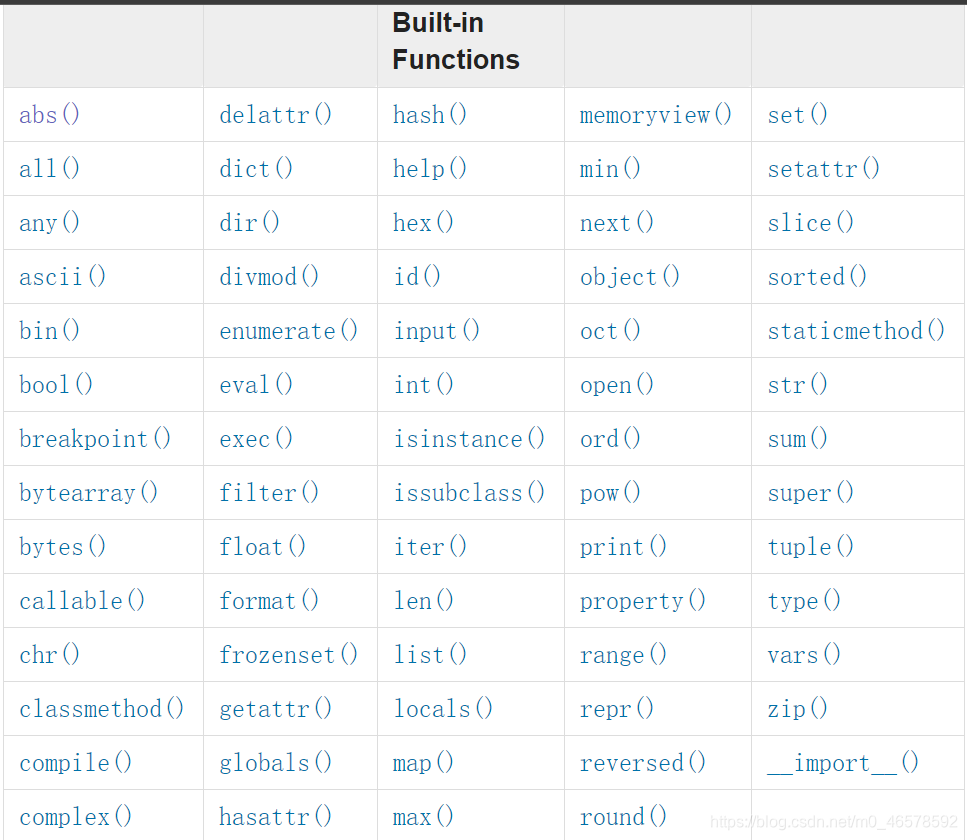
1.11.2 自定义函数
1 | ''' |
1.11.3 函数参数
- 默认参数:
默认参数必须指向 不可变的对象【如: str , tuple等】
如果默认参数为一个 list,则每次调用会记住上次调用的操作,造成结果不对
1 | ############### 默认参数 ############### |
- 可变参数(即:参数前加*):
允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple
1 | ############### 可变参数 ############### |
- 关键字参数(即:参数前加2个星号
*):允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict
1 | ############### 关键字参数 ############### |
- 命名关键字参数:
限制关键字参数的名字,命名关键字参数需要一个
特殊的分隔符*,后面的参数被视为命名关键字参数,如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了。命名关键字参数必须传入参数名。
1 | ######### 命名关键字参数 ################ |
2. Python 自动化办公
2.1 Excel 速查表

3. Python 爬虫(基本)
3.1 常用的爬虫库
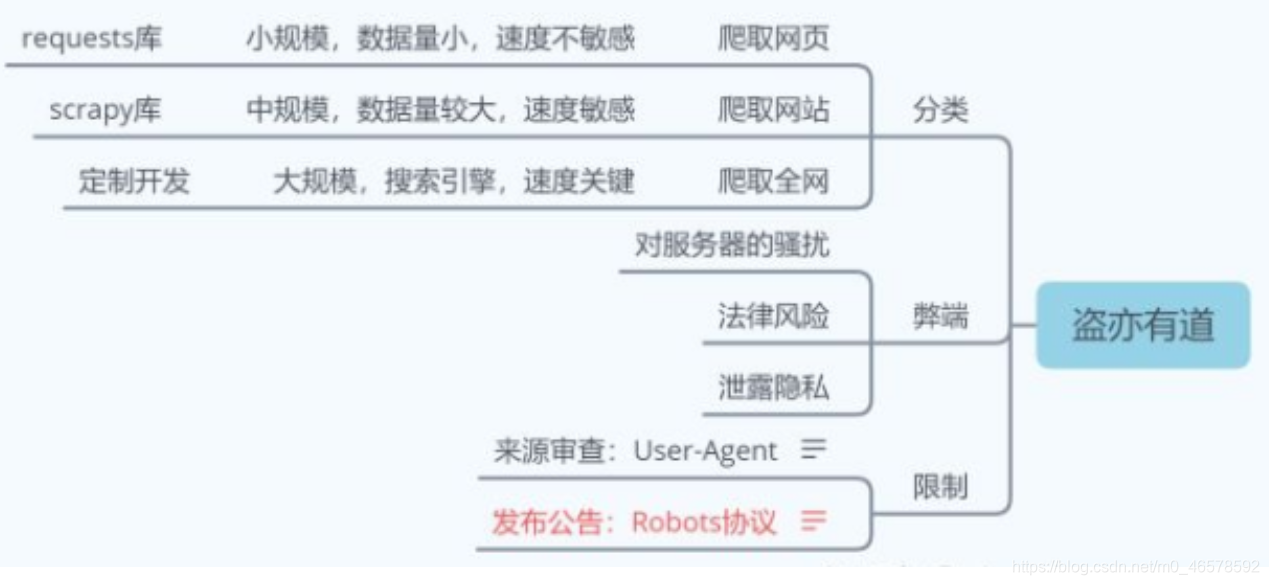
3.2 requests 库
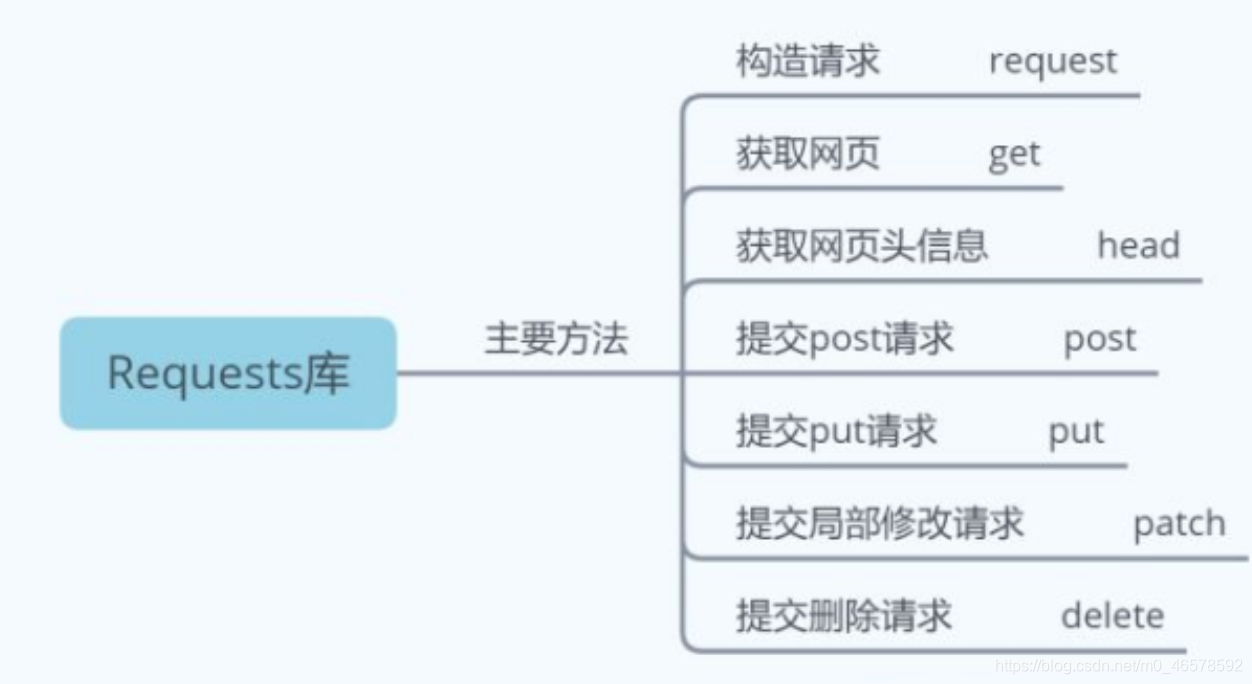
1 | import requests |
3.2.1 案例1 京东商品详情页
1 | #实例1:爬取京东商品详情页 |
3.2.2 案例2 亚马逊商品详情页
1 | #实例2:爬取亚马逊商品详情页————协议头 |
3.2.3 案例3 百度/360搜索关键字
1 | #实例3:爬取搜索页面 |
3.2.4 案例4 网络图片爬取及存储
1 | #实例4:爬取图片 |
3.2.5 案例5 IP地址归属地查询
1 | #实例5:IP地址归属地查询 |
3.3 urllib库
特点:不用安装,python自带
3.3.1 urllib基础:
1 | # 将网页保存到本地,参数为抓取的网址和保存网页的文件路径 |
3.3.2 urllib 库超时设置
根据 网速 和 对方服务器响应 的快慢设置相应的超时设置
1 | for i in range(0,100): |
3.3.3 自动模拟http请求:
3.3.3.1 get
常用于:搜索关键词,获得搜索界面
1 | #get请求 |
3.3.3.2 post
常用于:登录某些网站
1 | #post请求 |
3.4 bs4
来自:https://blog.csdn.net/qq_35490191/article/details/80598620
来源博客
功能: 解析、遍历、维护标签树。
例如:<p class='title'>...</p>
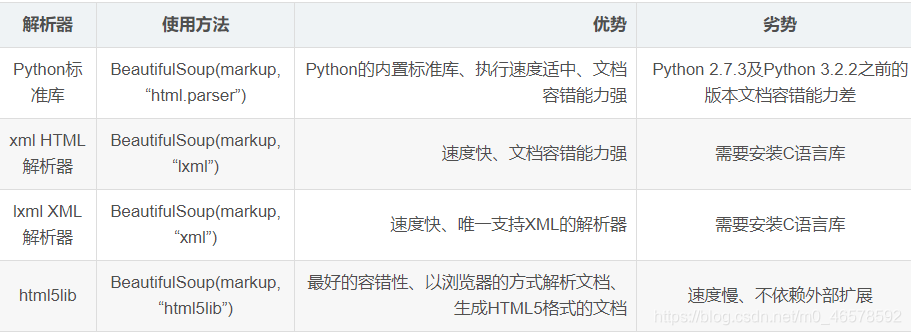
具体用法: soup=BeautifulSoup(markup,from_encoding="编码方式")
1 | html = """ |
Beautifu Soup将复杂的HTML文档转化为树形结构,每个节点都是Python对象:
- Tag:标签;
- NavigableString:被包裹在tag内的字符串;
- BeautifulSoup:表示一个文档的全部内容,大部分时候可以看做一个tag对象,支持遍历文档树和搜索文档树的方法;
- Comment:特殊NavigableString,会以特殊格式输出,比如注释类型。
3.4.2 bs4 基本用法
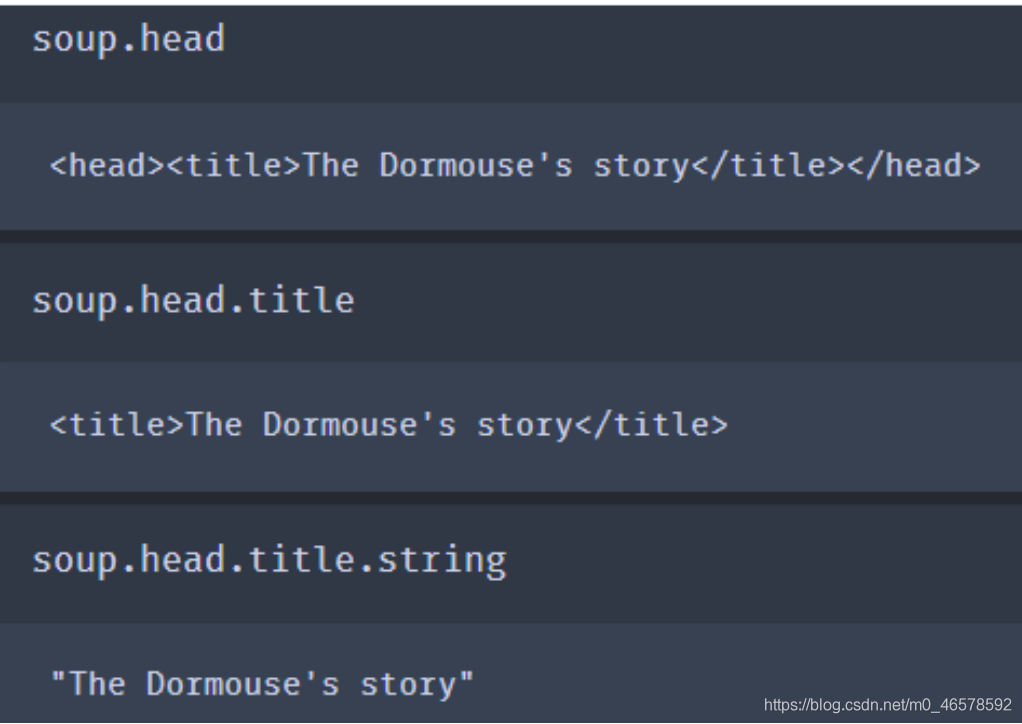
搜索文档树:soup.tag.property 按顺序获得第一个标签
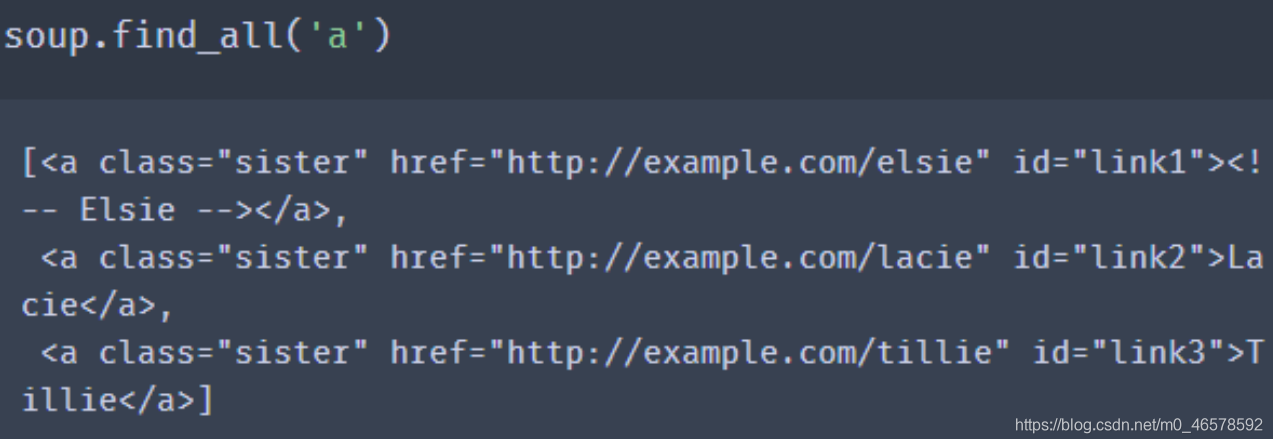
获取所有 ? 标签: soup.find_all( tag ) // 返回1个list
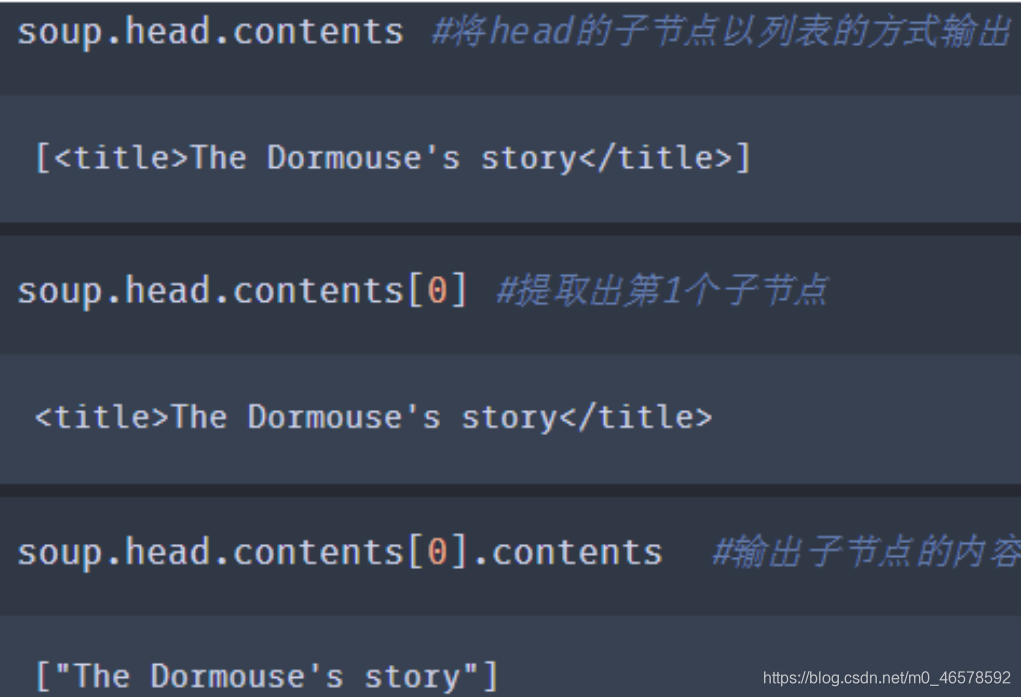
将tag的子节点以列表方式输出 : tag.contents
- 对tag的子节点 进行 循环 : tag.children
- 对tag的子孙节点 进行 循环 : tag.descendants

获取tag(只有一个子节点)下所有的文本内容 : tag.string
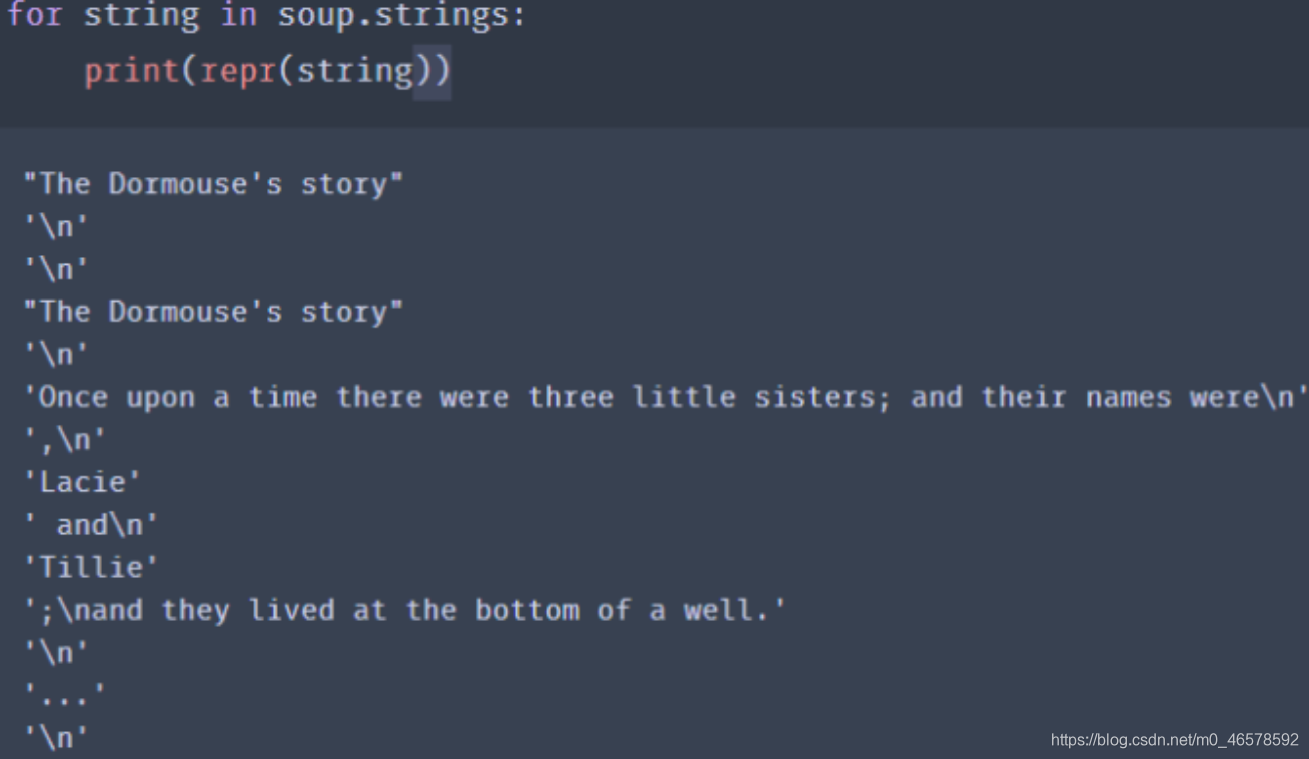
从文档中获取所有的文字内容 :soup.get_text( )

3.4.3 bs4 用法 思维导图
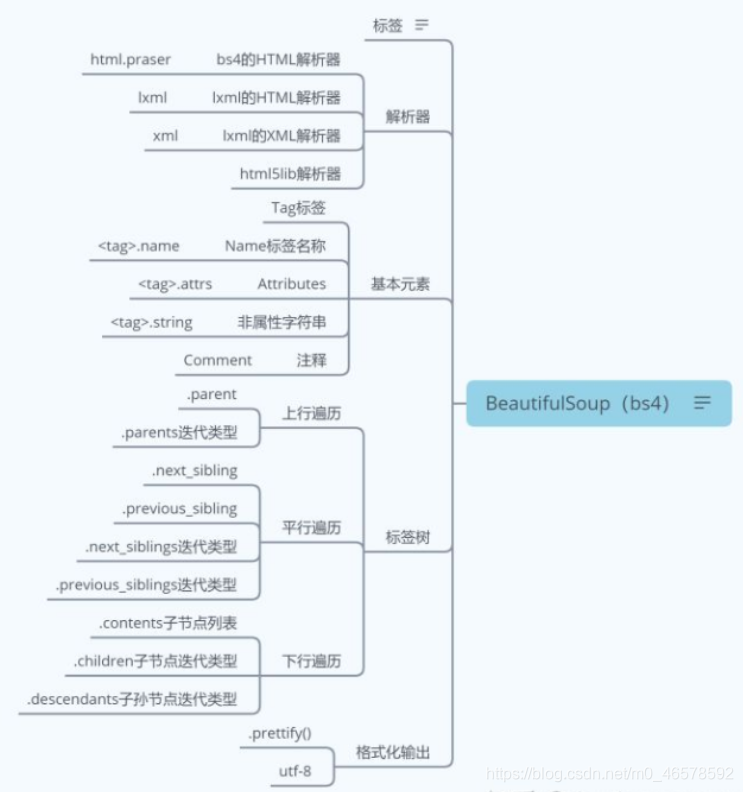
4、正则表达式
【用于提取信息】

4.1 正则表达式—思维导图
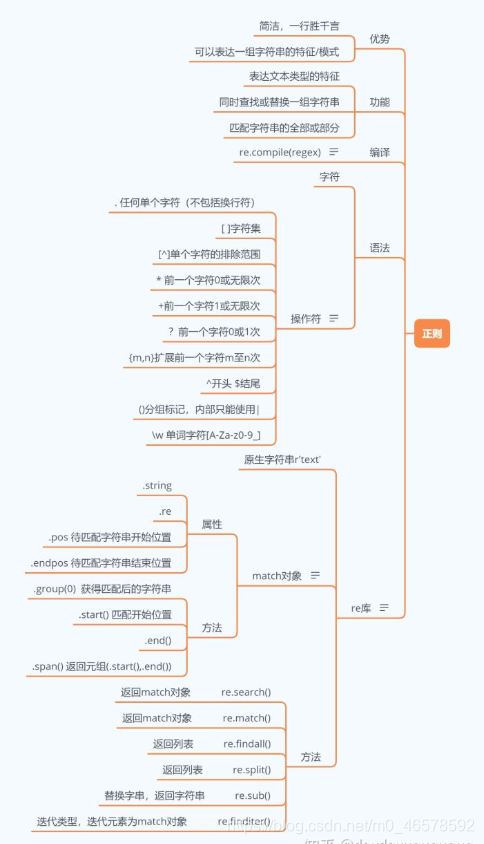
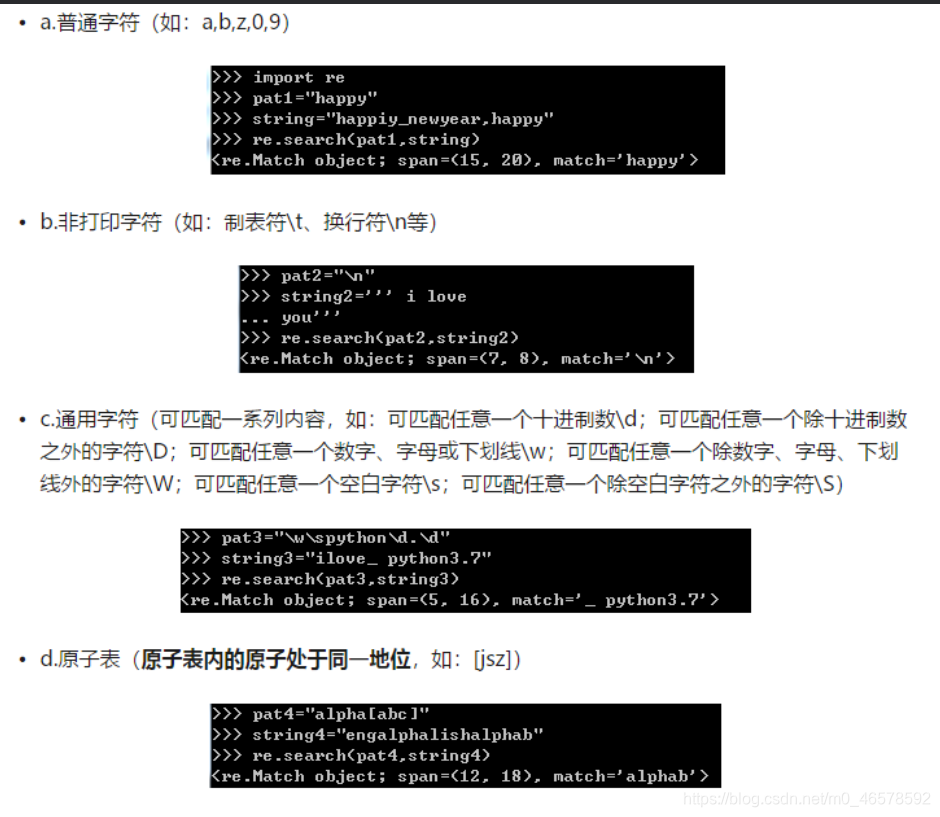
4.2 常见的原子类型-正则表达式最基本的单位
4.3 元字符-正则表达式中具有特殊含义的字符

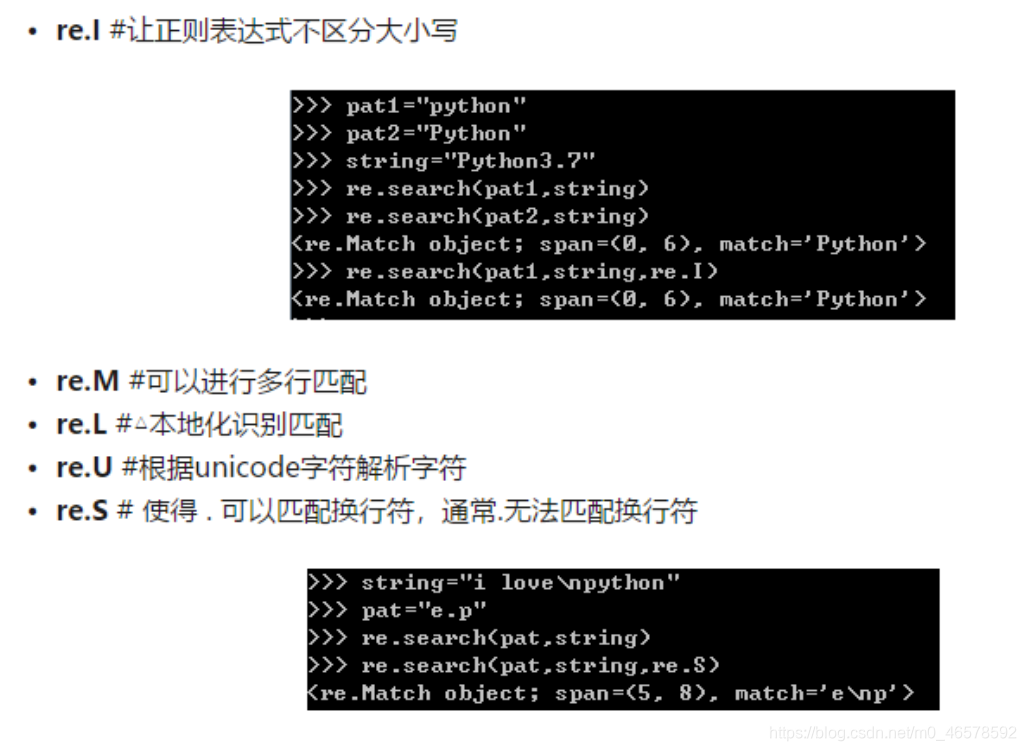
4.4 模式修正符-在不改变正则表达式的前提下,调整匹配结果
4.5 贪婪模式和懒惰模式
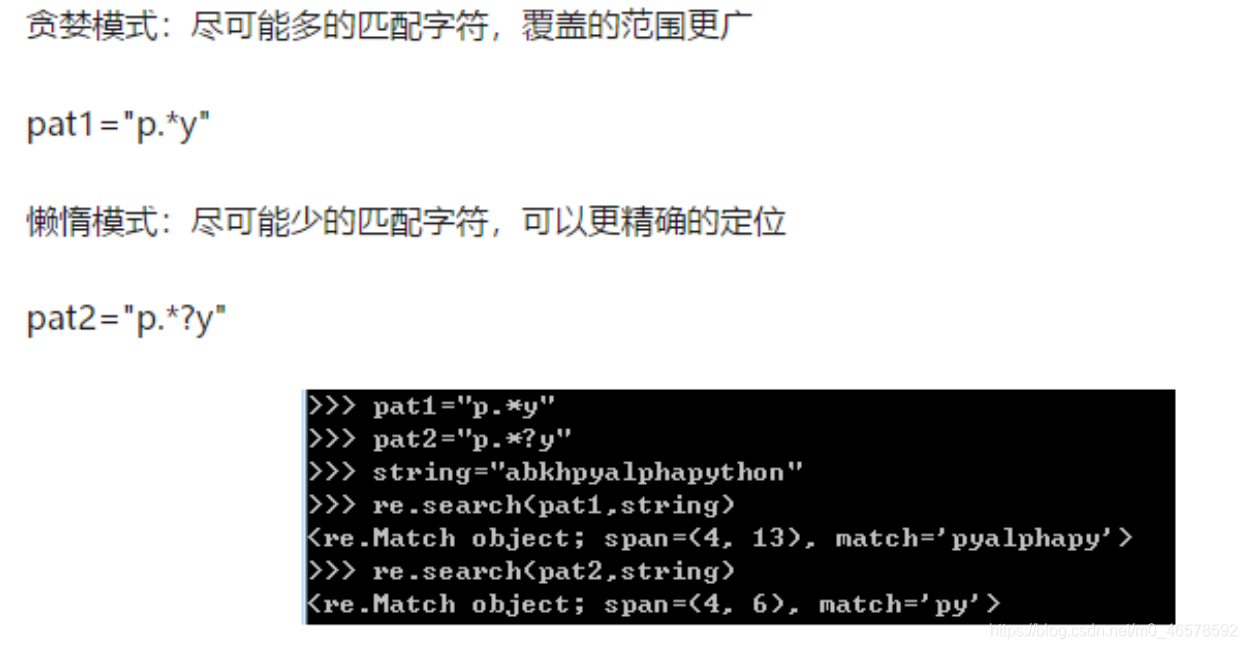
4.6 正则表达式函数

4.7 练习题:
5、Selenium
文档:Selenium with Python中文翻译文档 — Selenium-Python中文文档)
5.1、下载、配置浏览器驱动
注意:浏览器版本号要与驱动版本对应。
(1)下载:
谷歌驱动下载网站:chromedriver.storage.googleapis.com/index.html
火狐:Directory Listing: /pub/firefox/releases/ (mozilla.org)
(2)配置
将浏览器驱动解压后放入Python的安装目录(根目录)下。
(3)安装Selenium
1 | pip install selenium |
5.2、第一个Selenium示例
1 | # 导入Chrome浏览器的驱动 |
5.3、元素查找
driver 的查找方法:从4.0版本开始需要导入By类指定查找方式,常见的By类的查找方式:
1 | class By: |
实例:
1 | from selenium import webdriver |
5.4、元素信息
elem.get_attribute('属性名')
1 | from selenium import webdriver |
5.5、交互案例
需求:打开百度,输入周杰伦,点击搜索按钮,滚动到底部,点击下一页。
1 | from selenium import webdriver |
5.6、Chrome Handleless
由于原生的Selenium需要打开浏览器,使用界面,所以速度较慢,因此可以使用Handleless来进行无界面的操作。
案例:
1 | from selenium import webdriver |
封装成函数:
1 | from selenium import webdriver |
6. Scrapy 爬虫(网站级)
7、实例
1、二维码生成
1 | from MyQR import myqr |
2、姓名生成
1 | from random import randint |
 微信订阅号
微信订阅号

